¿Cómo detectar y resolver la Canibalización SEO en la web de tu eCommerce?
 Carlos Bravo
31 diciembre 2019
Carlos Bravo
31 diciembre 2019 
Las canibalización SEO son situaciones muy interesantes que debemos tener en cuenta a la hora de llevar a cabo nuestra estrategia de posicionamiento SEO, especialmente cuando nos referimos a un eCommerce, dado que por las características que tienen las webs de comercio electrónico suelen contener textos que pueden llegar a canibalizar su propio posicionamiento fácilmente.
¿Qué es la canibalización SEO?
La definición básica de una canibalización SEO vendría dada por aquella situación en que tenemos, en los resultados del buscador, más de una URL posicionada de nuestro sitio web para una misma intención de búsqueda.
Decimos por tanto que una URL está canibalizando a la otra.
¿Por qué hay que resolver las canibalizaciones?
Tenemos que tener en cuenta que, generalizando, para cada keyword o más concretamente, intención de búsqueda que queramos posicionar, sólo tenemos que orientar una URL hacia ella, estando esta URL optimizada para posicionar dicha query.
Si aparece más de una URL de nuestra web para la búsqueda de una keyword concreta suele ser porque el buscador no termina de tener claro cuál es la URL que satisface mejor dicha búsqueda.
El hecho de que el buscador no tenga claro cuál es la mejor URL para la búsqueda, implica también que el propio buscador les resta importancia a ambas URL’s, lo que significa que si el buscador se decidiese claramente por una URL y, por tanto, sólo apareciese esa URL, la misma tendría más importancia y aparecería más arriba, consiguiendo más clicks y más tráfico, lo cual se convierte en mayores conversiones y por tanto mayores ingresos.
Tipo de contenido en un eCommerce
Antes de entrar directamente a tratar las canibalizaciones, vamos a comentar por qué en un eCommerce tenemos que tener especial cuidado con ellas.
Empezaremos por hablar de los diferentes tipos de contenido que, generalizando, solemos encontrar en un negocio digital de este tipo:
- Texto de categoría: Se ubica en cada una de las categorías y subcategorías que aglutinan productos en nuestro eCommerce (por ejemplo en una tienda que venda productos informáticos la categoría de ordenadores portátiles).
Dichos textos suelen estar orientados a posicionar palabras clave o keywords genéricas (en este caso por ejemplo “ordenadores portátiles”) o transaccionales (por ejemplo “comprar ordenador portátil”).
- Texto de producto: Se ubica en cada una de las urls de producto y su objetivo es aportar información sobre el producto específico que estamos tratando en dicha url.
Estos textos están orientados a posicionar el nombre concreto del producto (por ejemplo “ordenador portátil Dell XXX”) o transaccionales sobre el producto (por ejemplo “comprar Dell XXX”).
- Texto de blog: Se usa para hablar de diferentes temas relacionados con el tipo de producto que se quiere vender, con el objetivo de posicionar otras keywords relacionadas que puedan traer más tráfico a la tienda.
Lo lógico es usar textos orientados a posicionar keywords informativas del tipo “mejores ordenadores portátiles 2019”.
Una vez visto el tipo de contenido que suele aparecer en un comercio electrónico veremos que la peligrosidad de generar canibalización SEO se encuentra precisamente en aquellos diferentes textos que tratan sobre la misma temática o temáticas extremadamente parecida, y esto suele ocurrir a menudo a través del blog.
Como he dicho arriba, siempre que se use correctamente, el blog de un eCommerce puede ser un recurso muy poderoso para generar tráfico de calidad que llegue a nuestra web y pueda derivar una buena parte hacia la tienda.
Sin embargo, tenemos que tener mucho cuidado al escribir en el blog porque podríamos canibalizar con las demás URL’s, sobre todo con las de categoría.
Si por ejemplo tenemos una categoría que habla sobre los “ordenadores portátiles” y un artículo del blog sobre los “mejores ordenadores portátiles” corremos el riesgo de que Google no sepa cuál es la URL más apropiada ante determinadas búsquedas relacionadas con la temática y perjudicar por tanto nuestro posicionamiento ante dichas keywords.
¿Cómo desarrollar contenido para un eCommerce?
Muchos pensaréis que la respuesta a este punto es sencilla: “pensando en el tema que se va a escribir y escribiendo”.
Sí, pero a la hora de escribir hay que tener en cuenta varios factores como por ejemplo qué tipo de estructura organizamos y cómo usamos las keywords LSI (palabras semánticamente relacionadas con la temática que aportan contexto al artículo y mejoran el entendimiento por parte del buscador) de cara no sólo a optimizar el posicionamiento, sino también a evitar una excesiva similitud con otros textos y reducir la posibilidad de generar una canibalización.
El consejo principal en este asunto sería básicamente observar qué es lo que ya posiciona en Google, porque aquellos resultados que se sitúen más arriba en los resultados cuando buscamos las palabras clave a las que nos queremos enfocar, serán los que tengan una estructura más apropiada y un mejor uso de las keywords LSI, dado que Google lo ha valorado así.
Para ello deberíamos de observar cada uno de los textos revisando cómo están estructurados y hacer un análisis de las keywords LSI en base a cantidad de las mismas y proporciones con respecto a volumen total del artículo, tanto para expresiones de una sola palabra como también para expresiones de 2 ó 3 palabras que puedan conformar en algunas ocasiones pequeñas frases.
Las medias de estos datos nos darán una imagen clara de lo que debemos de hacer a la hora de escribir.
Si tras leer el anterior párrafo, te has puesto a sudar te puedo decir que, si bien el proceso se puede realizar a mano, existen diversas herramientas con fórmulas derivadas del TF*IDF (algoritmo usado principalmente en sistemas bibliotecarios que detecta la importancia de determinadas palabras en un conjunto de documentos) que te darán los datos de una manera mucho más simple, como pueden ser Seolyze, con su EPS*KF:

Otra que desde hace poco destaca por ofrecernos esta métrica es DinoRANK con su WDF*DF:

Ésta aporta además una muestra de la estructura de encabezados de los primeros resultados de Google.
¿Cómo detectar la canibalización SEO en mi Web?
Como hemos dicho anteriormente, una canibalización se produce cuando, en los resultados del buscador, aparecen 2 urls de nuestro sitio web para la búsqueda de una determinada keyword o, más concretamente, una intención de búsqueda.
Según ésto tendríamos que ir realizando sistemáticamente las búsquedas de las keywords que queremos posicionar y después analizar los primeros 100 resultados (al menos) para ver si en alguna de las palabras clave a posicionar los resultados incluyen alguna duplicidad de urls.
Ni que decir tiene que este proceso lo debemos de hacer cada poco tiempo, dado que los resultados del buscador van cambiando y aunque para una determinada búsqueda no existan canibalizaciones se puede dar el hecho de que poco después surja una.
De nuevo nos encontramos con un proceso que puede ser un tanto tedioso, pero de nuevo tenemos también la opción de utilizar herramientas que nos indicarán aquellas canibalizaciones que puedan encontrar.
Sistrix es una de las herramientas que nos mostrará canibalizaciones que podamos tener en aquellas keywords que ellos rastrean por defecto.

En el caso de DinoRANK, nos mostrará las canibalizaciones en dos niveles: por un lado analizará si en aquellas palabras clave cuyo posicionamiento estamos monitorizando se da alguna canibalización:

Y por otro lado, si lo sincronizamos con nuestra cuenta de Search Console, extraerá los datos necesarios de Google para mostrarnos otras canibalizaciones más allá de las keywords que monitorizamos.
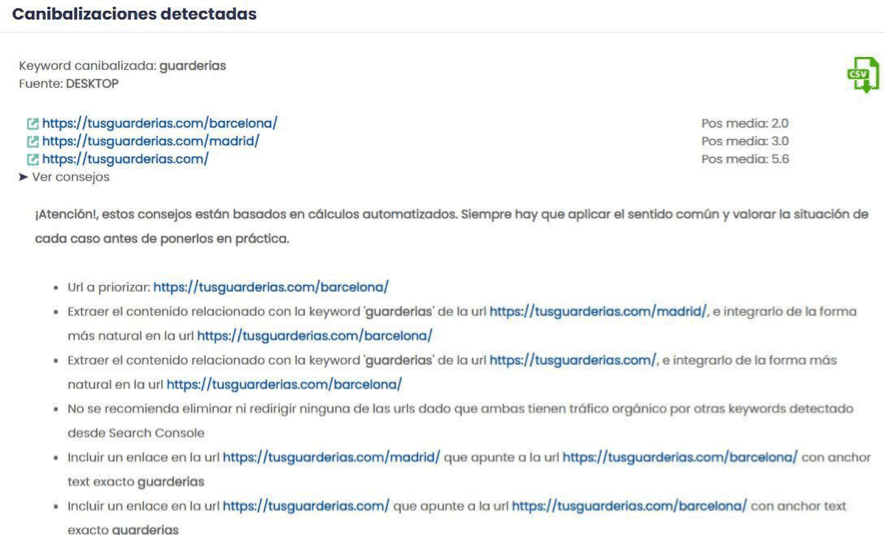
Resolviendo canibalizaciones SEO
Los pasos a dar para resolver una canibalización SEO son un tanto mecánicos pero dependen básicamente de la situación de las urls que canibalizan, especialmente de la URL que queremos que deje de figurar en el listado de resultados del buscador.
Lo primero que tenemos que hacer es tener claro qué URL queremos que permanezca (la llamaremos “primaria”).
Lo lógico es que mantengamos la URL que posiciona más alto, pero se pueden dar algunos casos especiales en que no nos interesa mantener la URL mejor posicionada en base a nuestro propio criterio.
Cuando tenemos claro qué URL queremos eliminar de los resultados de búsqueda (la llamaremos “secundaria”) tenemos que mirar si dicha URL recibe tráfico orgánico por otra keyword diferente a la keyword canibalizada.
Esta información la podremos encontrar mediante Search Console y/o Google Analytics.
En el caso de que la URL no tenga más tráfico orgánico tenemos que plantearnos si nos interesa mantener la existencia de dicha URL por requerimientos del negocio independientemente de su capacidad para posicionar.
Por ejemplo se puede dar el caso de que una página legal pudiese canibalizar en alguna keyword y fuese necesario mantener dicha página legal.
Tras haber hecho estas reflexiones pasaremos a la acción.
✅ Sin tráfico de otras keywords en URL secundaria y sin necesidad de mantenerla:
En el caso de que la URL “secundaria” no tenga tráfico orgánico por otras keywords y además no necesitemos mantenerla por requerimiento del negocio estamos ante la situación más sencilla:
Procederemos integrando el contenido que podamos desde la URL “secundaria” a la URL “primaria”, de la forma más natural posible, para enriquecer el contenido de ésta última.
Tras eso haremos una redirección 301 de la URL “secundaria” a la “primaria”.
Como último paso deberíamos de cambiar los enlaces que apuntaban a la URL “secundaria” para que apunten a la “primaria”, aunque este paso lo podemos posponer en caso de no poder ejecutarlo inmediatamente.
✅ Si necesitamos mantener la URL secundaria y hay tráfico de otras keywords:
En el caso de que necesitemos mantener la URL “secundaria” procederemos a extraer de la misma aquel contenido que estimemos que está relacionada directamente con la keyword y pasarlo a la URL “primaria” de forma natural.
También intentaremos eliminar (en la medida de lo posible) la keyword que se posiciona, de elementos importantes de la página como el Title o los encabezados (H1, H2, …).
Después intentaremos localizar enlaces que apuntasen a la URL “secundaria” y, siempre manteniendo la coherencia, los apuntaremos a la URL “primaria”, en los casos en que sea posible sin afectar al significado de dicho enlace.
✅ Si necesitamos mantener la URL secundaria pero no hay tráfico de otras keywords:
Si, aparte de necesitar mantener la URL “secundaria” dicha URL no tiene tráfico orgánico por otras keywords también pondremos una etiqueta canonical en la URL “secundaria” que apunte a la URL “primaria” y marcaremos noindex en la etiqueta meta robots.
A destacar que una de las herramientas de detección de canibalizaciones que hemos tratado anteriormente, DinoRANK, también nos indicará qué pasos debemos de seguir para resolver aquellas canibalizaciones detectadas mediante sincronización con Search Console.
Pero, eso sí, debemos de tener siempre en cuenta que estos consejos son automatizados por lo que en algún caso podrían contraponerse con respecto a nuestros propios intereses personales.
Conclusiones
La canibalización SEO son fenómenos que puede afectar negativamente a nuestro posicionamiento en buscadores, posicionamiento del que depende en buena parte la cantidad de ventas que tenga nuestra tienda online.
Es conveniente resolver todas las canibalizaciones ya que eso hará que mejoremos nuestro posicionamiento orgánico.
Mediante los consejos desarrollados en este artículo podremos detectarlas y resolverlas, ya sea de manera totalmente manual o usando herramientas, aumentando nuestro tráfico y por tanto también nuestros ingresos.
